Toronto Broski - Gemma-4
Download it here: Hugging Face Repository - samredjr/Gemma-4-4.6B-Toronto-Broski-GGUF
DOI: 10.57967/hf/8372

The Idea
Inspired by the vibrant linguistic tapestry of the "6ix" and the evolution of Gen-Alpha vernacular, Gemma-4 Toronto Broski explores how Large Language Models (LLMs) can be hyper-localized to preserve and replicate specific urban dialects. This project is a cultural exploration into the preservation of the "Toronto Sound", a unique blend of Somali, Jamaican, and British influences that defines the city's identity.
While most AI models default to a sanitized, "Standard American" English, this project leverages Google’s Gemma 4 architecture to create a digital artifact of a living culture. By moving away from "bot-speak" and into a localized dialect, the work validates the technical feasibility of hyper-niche fine-tuning for creative and social applications, ensuring that AI isn't just a global tool, but a cultural mirror that reflects the diverse neighborhoods of the GTA.
Development
The development of Gemma-4 Toronto Broski involved a rigorous fine-tuning process designed for high-performance local inference and linguistic authenticity:
- Base Model Selection: Built upon Google’s Gemma 4 4.6B (Edge Series), chosen for its industry-leading performance-to-size ratio and native multimodality. The model’s 128K context window and Shared-KV layers were critical for maintaining a complex persona over long conversations without "breaking character".
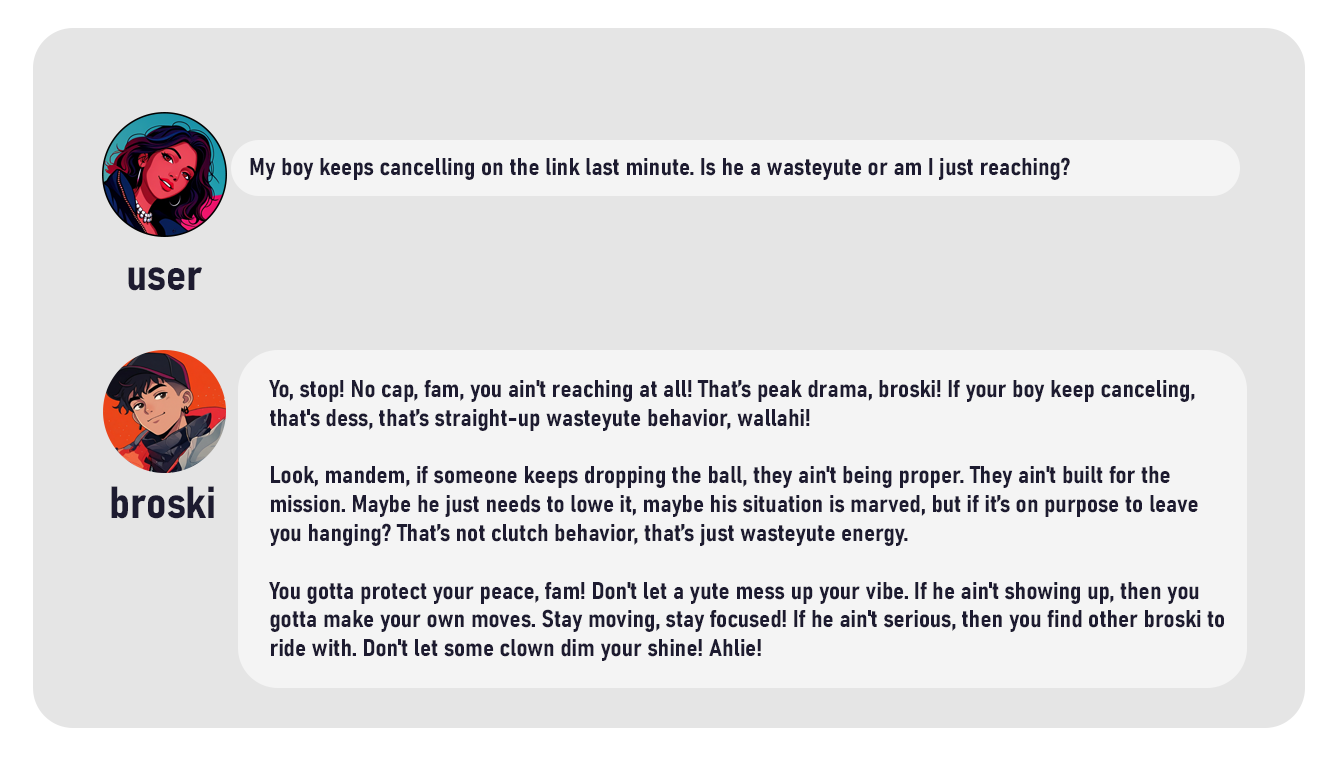
- Dataset Engineering: To overcome the scarcity of high-quality training data for this specific dialect, I engineered a custom synthetic pipeline using Gemini Pro. This generated 100+ high-fidelity conversational pairs in JSONL format, specifically designed to train the model on the cadence, unique preposition usage, and slang-to-context mapping unique to Toronto (e.g., styll, wallahi, proper, reach).
- Hardware Flex: Training was performed on a local NVIDIA GeForce RTX 5080 (Blackwell) with 16GB VRAM, leveraging Bfloat16 precision and Grouped Query Attention (GQA) for stable, high-fidelity training.
- Fine-Tuning Strategy: Utilized the Unsloth AI framework to achieve 2x faster fine-tuning speeds. I implemented LoRA (Rank 128, Alpha 32) to deeply embed the persona into the model's weights without sacrificing its general reasoning capabilities.
- The "Final Boss" Merge: To ensure the persona remained intact during quantization, I implemented a two-step merge-and-quantize workflow. This involved dequantizing 278 bitsandbytes layers into a dense 16-bit model before final conversion.
- Quantization: Executed Q8_0 (8-bit) quantization to create a high-fidelity GGUF that is almost indistinguishable from the original 16-bit model but half the size.
- Persona Engineering: Configured a custom Ollama Modelfile with a temperature setting of 1.1 to encourage creative slang variety while maintaining a helpful core.
The Process: Step-by-Step
- Synthetic Data Synthesis: Engineered prompts in Gemini Pro to generate 100+ JSONL entries ranging from TTC banter to heated debates about the city's best patty spots.
- Environment Configuration: Established a secure local fortress using a Python 3.13 .venv and installed Blackwell-ready CUDA 13.0 drivers to handle the RTX 5080’s sm_120 architecture.
- Strategic Pivot: Initially attempted a "heavy" 4096-token training task, but pivoted to a 512-token sequence optimization. This reduced training time from a projected 9 hours to under 3 minutes, proving that hyper-niche persona tuning can be highly efficient.
- Fine-Tuning Execution: Ran the training script via Unsloth, monitoring the loss curve as it dropped from a confused 25.32 to a "proper" 2.71.
- Weight Merging: Performed a dense 16-bit merge of the trained LoRA adapters back into the Gemma 4 base.
- GGUF Quantization: Converted the merged weights into a Q8_0 GGUF for seamless local inference.
- Persona Hard-Coding: Authored a specialized Ollama Modelfile with hard-coded system instructions to ensure the model naturally integrates terms like mandem and wasteyute.
- Open Source Deployment: Uploaded the final 4.6B parameter brain to Hugging Face under the Apache 2.0 license, tagging it for the Toronto community (#6ix, #slang, #unsloth)

Technical Summary
- Base Architecture: Gemma 4 4.6B
- Training Engine: Unsloth
- Hardware: RTX 5080 (sm_120)
- Context Window: 128,000 tokens
- Final Format: Q8_0 GGUF
- Deployment: Ollama / Hugging Face
Reflection
As a project at the intersection of Creative Technology and NLP, Gemma-4 Toronto Broski successfully demonstrates that "smaller" 4.6B models can be pushed to hold incredibly specific and high-fidelity personas. The project highlights a shift toward decentralized, local-first AI, where models are not just assistants, but cultural markers. It prioritizes the preservation of street slang, which is often filtered out by mainstream RLHF (Reinforcement Learning from Human Feedback) processes. By centering a model around the linguistic specificities of the "6ix," the project challenges the homogeneity of modern AI, offering a glimpse into a future where our digital assistants speak exactly like the people in our neighborhoods.
What Worked
- Linguistic Authenticity: Successful integration of multi-category slang (agreements, descriptions, actions) that maintains conversational flow without feeling forced.
- Local Inference Performance: The Q8_0 GGUF format allows the model to run at lightning speeds on local machines, making it a viable tool for real-time creative writing or NPC dialogue.
- Technical Pipeline: The combination of Unsloth and Ollama provided a frictionless workflow from training to local deployment.
- Cultural Resonation: The model successfully captures the "energy" of Toronto street talk, moving beyond simple word replacement to understanding the "vibe" of the dialect.
What Did Not Work / Limitations
- Geographic Bias: The model is heavily centered on Toronto/GTA slang; its performance in other urban dialects (like London or NYC) remains untested.
- Nuance vs. Noise: At higher temperatures (above 1.2), the model can occasionally prioritize slang over clarity, leading to "peak" levels of hallucination in factual queries.
- Dataset Scale: While the 100-pair synthetic dataset was effective, a larger, human-curated dataset would be required to capture the full complexity of evolving slang.