◉–◉ FrameVision
The Idea
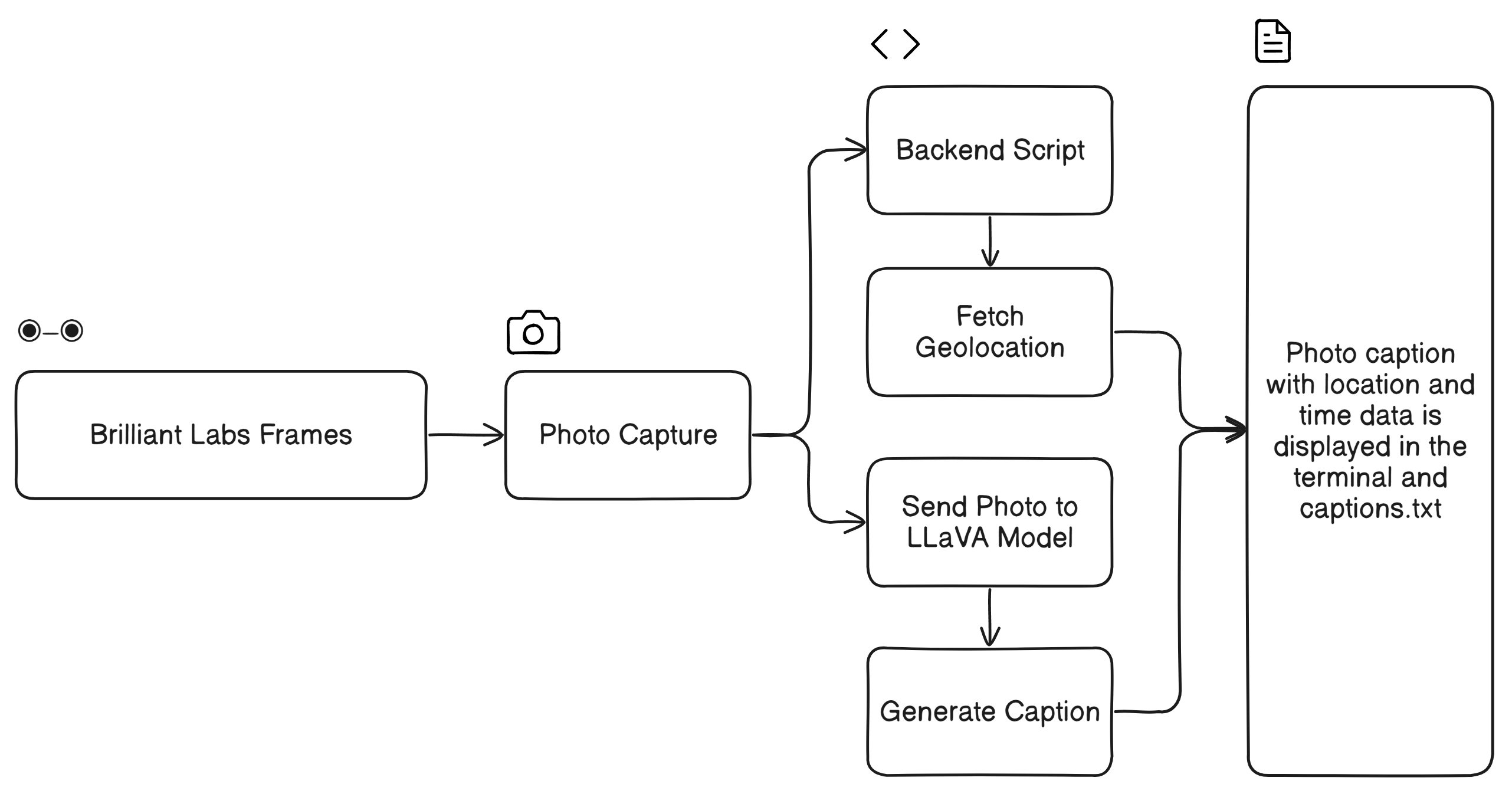
FrameVision integrates Brilliant Labs Frame smart glasses with the LLaVA Vision-Language model to deliver smart image capturing paired with geolocation and textual descriptions. The system captures moments in real time, extracts location data via IP-based services, and generates contextualized descriptions using a locally hosted LLaVA model. This combination of augmented reality hardware and AI enables users to log spatially enriched memories seamlessly.

Development
The project utilized Python to orchestrate communication between the Frame smart glasses and the LLaVA model. Captured photos were processed locally using Ollama's API to generate meaningful textual descriptions. Geolocation was retrieved through IP-based services and appended to captions with timestamps. Despite its robust functionality, achieving smooth Bluetooth pairing with the Frame and optimizing the API communication required significant debugging.
Reflection
The system succeeded in delivering spatially and semantically rich image logs, demonstrating the feasibility of combining AR hardware with AI-driven descriptions. However, the reliance on IP-based geolocation limited precision in some scenarios. While this proof-of-concept showed promise, further iterations could include GPS integration for higher accuracy and advanced interactivity for refining generated captions.
What Worked
- Reliable image capture with Frame smart glasses.
- Accurate textual descriptions of captured images.
- Efficient logging of timestamps, descriptions, and geolocations.
What Did Not Work
- Limited precision of IP-based geolocation.
- Occasional delays in API response for high-frequency image captures.
- Negligible AR immersion
- Image quality was poor, with visible banding and noise artifacts.
- Nighttime image capture suffered from excessive color banding, making the photos nearly unusable in low-light conditions.
Github
calluxpore/FrameVision-Smart-Image-Capture-Description-with-Location